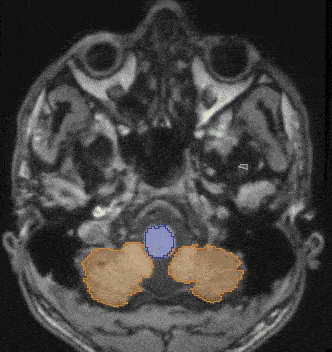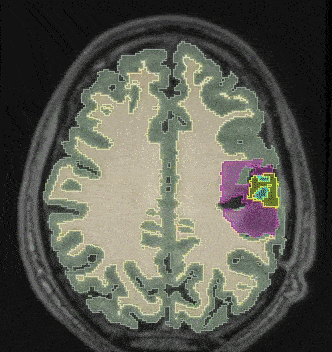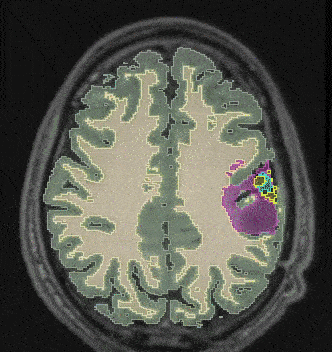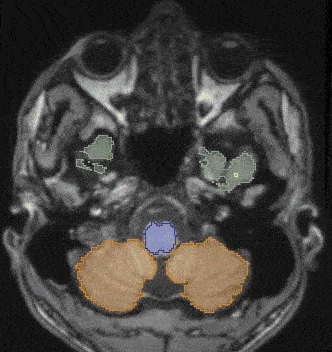
Learning high-dimensional latent representations from different imaging modalities
Machine learning algorithms often struggle with incomplete sets of images. Our solution addresses this issue by creating a shared, high-dimensional image representation of multimodal images. Extending multi-modal VAEs with a hierarchical latent structure, we introduce a probabilistic formulation is introduced for fusing multi-modal images in a common latent representation while having the flexibility to handle incomplete image sets during both training and testing. This solution is particularly useful in scenarios where the data available for analysis may be incomplete.